“我们力争在未来十年内再实现百万倍的提速,我迫不及待的想知道下一个Million-X将会带来怎样的变化。”
北京时间3月22日晚23时,NVIDIA召开新一年度GTC大会。会中,NVIDIA(英伟达)创始人兼CEO黄仁勋发布出四款即将面世的新品,NVIDIA H100、Grace-Hopper、NVIDIA Omniverse、NVIDIA Spectrum-4 51.2Tb/s的交换机。
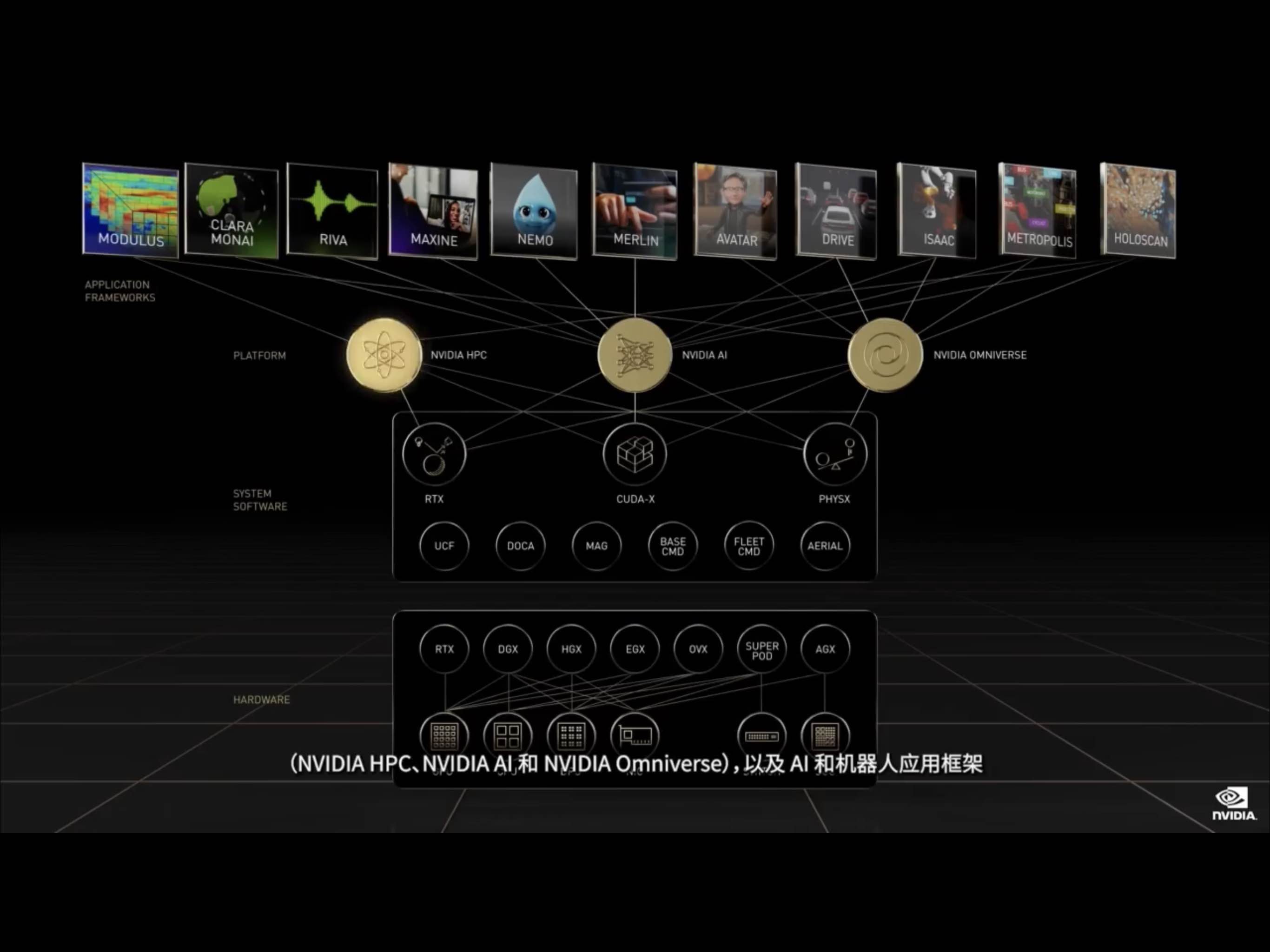
本次发布的新品延续2021GTC产品区间,围绕NVIDIA硬件、系统软件、库及软件四层技术栈,从NVIDIA HPC、NVIDIA AI、NVIDIA Omniverse、AI及机器人应用框架五个维度再次推进基于ARM架构的Grace数据中心、自动驾驶、虚拟人等技术发展,再次将NVIDIA加速计算、数据中心级全栈工程优化使计算速度提高了百万倍。
“自主学习的发明使得AI发展速度越上新高,而AI已从根本上改变了软件的能力以及开发软件的方式,NVUDIA通过提炼数据来打造AI、构建智能,其数据中心就是AI工厂。”黄仁勋自豪放言,NVIDIA AI是一套从数据处理和ETL特征工程到图形、经典机器学习、深度学习模型训练及大规模推理AI流程,涵盖整个AI工作流程的库,NVIDIA DALI、RAPIDS、cuDNN、Triton、Magnum IO能够用来创建专用AI框架及预联系模型。
数据、CPU、虚拟人、供应链优化……乘上AI东风的NVIDIA这是要做什么?
尽管NVIDIA近日已正式宣布收购ARM计划弃置,但从其发布的新品上已然能感受到两者合作仍在不断加深。从新品看,NVIDIA不减以往扩张发展态度,表现出强势攻击性。其同步推出的能够在CPU和GPU之间直接链接的单一超级芯片模组——Grace-Hopper,能够在CPU与GPU之间直接进行芯片间的直接连接。这是否意味NVIDIA正式进军CPU+GPU行列?
01
NVIDIA H100:全球AI基础架构新引擎

在此次发布会上,黄仁勋首款发布的新品便是H100GPU。
这款芯片采用Hopper架构,是首款支持PCle5.0标准的GPU,也是首款采用HBM3标准的GPU。拥有强大的性能,4PetaFLOPS的FP8、2PetaFLOPS的FP16、1PetaFLOPS的TF32、60TeraFLOPS的FP64和FP32。风冷和液冷设计,是首个实现性能扩展至700瓦的GPU、单个H100可支持40Tb/s的IO带宽。
同时,Hopper引入Transformer引擎,让新Tensor Core与能使用FP8和FP16数字格式的软件结合,将模型训练时间从数周缩短为数日;云计算方面,增加7个云租户托管;实现首个GPU加密计算;引入DPX指令集,将算法速度加快40倍;用NVLink Switch芯片相连,实现AI计算计算系统产生。
在海量数据处理普遍存在的情况下,增速计算速度将大大缩短研发周期。对此,黄仁勋表示,从另个角度来说,20块H100GPU便可承托相当于全球互联网的流量。而在AI处理方面,Hopper H100 FP8的4PetaFLOPS性能是AmpereA100 FP16的6倍,这是一次巨大的代际飞跃。
02
能将Grace CPU便捷相连的模组——Grace-Hopper

Grace Hopper是一款单一超级芯片模组,拥有超节能、低延迟、高速内存一致性、拓展便捷的优势。
借助NVLink可以将两个芯片通过MVLink连接,组成超级芯片。重组后的Grace超级芯片拥有144个CPU核心,内存带宽1TB/s,是NVIDIA尚未发布的第5代顶级CPU的2到3倍。整个模组的功率仅为500瓦,节能性极强。同时这款CPU还将得到NVIDIA所有软件平台的支持。
发布会中,黄仁勋自信称,Grace将在AI、数据分析、科学计算和超大规模计算领域崭露惊人表现。目前,几乎没有任何产品可与之媲美。而Grace CPU芯片预计将于2023年进行供货。

NVLink现在应用于裸片之间、芯片之间和系统之间的互联,并能够提供多种Grace-Hopper系统配置方式。例如,2个Grace、1个Grace加1个Hopper、2个GRACE加8个Hopper。
未来,包括CPU、GPU、DPU和SOC的所有芯片都将支持NVLink,英伟达还将为客户和合作伙伴提供NVLink,以构建配套芯片。而NVLink支持NVIDIA平台和生态系统构建半定制芯片和系统。
03
Omniverse:模拟世界的终极挑战
“NVIDIA Omniverse平台适用于虚拟世界、数字孪生和机器人系统的特性将掀起下一波AI热潮。”
20多年来,NVIDIA在图形、物理学、仿真、AI等技术深耕,最终发布出虚拟世界仿真引擎——Omniverse。这款产品能够将设计师、观看者、AI、机器人进行连接,在协作办工、工业孪生、机器人学习等领域拥有生产空间。
设计师应用:Omniverse Cloud
设计师在进行3D设计师,因应用、硬件、工作地点的不同而难以进行项目协同,Omniverse Cloud能够帮助设计师便捷进行操作。在这个软件中,可以使用AI与员工共同合作,提升工作效率。

另外,NVIDIA开发本次还开发出构建数字人的框架Omniverse Avatar。这一软件能够利用语音AI、面部动画、开源材质定义语言等技术对数字人进行构建,并且,在经过TOKKIO语言模型训练后能够与人进行眼神交流及对话。
黄仁勋表示,下一波AI浪潮是机器人,AI也有相应计划和行动。当下,NVIDIA正在构建多个机器人平台,其中包括自动驾驶DRIVE、控制系统Isaac、自主基础架构的Metropolis、医疗机器人Holoscan。
04
NVIDIA Spectrum-4 催生机器人系统
如同TensorFlow和PyTorch是面向感知的AI基本框架一样,DXG是AI工厂的基础架构,OVX是数字孪生的基础架构。
OVX运行Omniverse数字孪生,多用于大规模仿真,需要实现多操作系统在同一时空运行。而Omniverse软件和计算机必须具备可扩展、低延迟和支持精确时间的特点,因此,NVIDIA建立起同步性数据中心。
据黄仁勋介绍,NVIDIA Spectrum-3 200Gbps交换机在连接32台OVX服务器后构成的OVX SuperPOD,能够精准时间协议进行同步,同时降低数据延迟,所以现阶段正由NVIDIA及早期客户运行着。第二代OVX正在从骨干网络进行构建。
此次,NVIDIA推出的首款400Gbps的端到端网络平台——NVIDIA Spectrum-4 51.2Tb/s交换机。拥有ConnectX-7和BlueField-3适配器及DOCA数据中心基础架构软件,能够组成世界上首个400 Gbps端到端网络平台,能够实现纳秒级计时精度,该款产品样品将于第三季度问世。
无独有偶,Spectrum-4 催生出一种作用于云和边缘数据中心支持Omnoverse数字孪生的新型机器人。
当不同生态系统经由Omniverse生成统一工作流程时,其价值将被放大。基础架构设计平台Bentley将Omniverse集成于LumenRT平台中,发布出二合一平台,成功放大交互性、工程级4D可视化性能,达成1+1>3的效果,加大工业效用。
“能够感知、规划并采取行动的机器人系统将引领下一波AI浪潮。”黄仁勋感叹道。
随着机器人和工业自动化时代变革滚滚而来,机器人系统逐渐成为抢占先机的核心。技术发展推动企业不由自主向前,而NVIDIA恰好就站在了发展前列。基于真值数据生成、AI模型训练、机器人技术栈和Omniverse数字孪生构建的端到端全栈机器人平台NVIDIA Avatar、Drive、Metropolis、Lsaac和Holoscan被逐一提上台面,Omniverse也成为这些机器人平台的中心。
近年来NVIDIA布局方向逐渐向广,涉及领域包含AI工厂、CPU+GPU、虚拟平台架构、机器人系统,从一系列动作来看,其目标不只是从一家GPU企业转型计算平台。受益现阶段先手布局,未来NVIDIA在工业互联、机器人系统等科技场景中都具备发展可能性。此次发布会推出的Grace-Hopper解决了此前NVIDIA需要解决的带宽问题,发展潜力强劲。并且,现阶段芯片产业正逢从单一架构计算单元转向CPU+GPU异构阶段,而技术更迭所带来的巨头震荡发生于法只是时间问题。笔者认为,从长远看,NVIDIA布局于未来利好性强,更加具有地位可提升潜力。


重磅!宁德时代前执行总裁朱威,加盟地平线任总裁

“ 贾跃亭 ” 发布三大系列EAI机器人,预定单达1211台

理想汽车组织架构调整:研发体系重组为三大团队,原自动驾驶负责人郎咸朋将负责机器人研发


