本文发自venturebeat,原题为“How bias creeps into the AI designed to detect toxicity”,作者Kyle Wiggers,经朋湖网作者王姿蝶编译整理,供业内参考。
2017 年,谷歌的反滥用技术团队和谷歌母公司 Alphabet 旗下的 Jigsaw 组织发布出一款用于内容审核的人工智能 API——“ Perspective”,其主要功能是“识别可能破坏民间思想交流的有害评论”。这款API可以通过新评论与有害评论进行对比来确定新评论是否属于有害对话。Jigsaw声称,其AI能够迅速生成比关键字、黑名单更准确的“毒语”评估。
然而,研究结果表明,此类技术若要完善仍需克服极大挑战,例如应对特定用户子集的偏见。
近来,宾夕法尼亚州立大学研究团队发现,社交媒体上有关残疾人的帖子可能会被常用公众情绪和毒性检测模型标记为负面或有害。于是,研究团队对其中几个模型进行了训练,在将这些训练后的模型用于Jigsaw的开放基准测试时,该团队观察到这些模型学会了将“负面情绪”词如“毒品”、“无家可归”、“成瘾”和“枪支暴力”以及带有负面情绪的“瞎子”、“孤僻症”、“聋子”和“傻子”等词与残疾联系起来。
“最大的问题是它们是公共模型,很容易用来根据情绪对文本进行分类。”该论文的合著者Pranav Narayanan Venkit博士和Shomir Wilson助理教授通过电子邮件告诉 VentureBeat,“结果很重要,因为它们表明机器学习解决方案并不完美,以及该如何对技术负责。这种彻头彻尾的歧视是对社区有害的,因为它不能准确地代表这些社区或语言。”
01
偏见的出现
据研究表明,语言模型会放大它们接受训练的数据中的偏差。
例如,OpenAI 开发的代码生成模型 Codex 在输入“Islam”一词时会提示写“terrorist”。Cohere的另一个大型语言模型倾向于将男性和女性与刻板印象的“男性”和“女性”职业联系起来,例如“男性科学家”和“女性管家”。
这种情况是由于语言模型的检测方式导致的,一般来说,语言模型的检测是通过单词或单词序列的概率分布进行分解。
实践过程中,模型对单词序列“有效”的概率进行了录入——即类似于人们写作的方式。一些语言模型在训练过后学会了对性别、种族、民族、宗教与负面词组合的分辨,但负面词在文本中使用过多。
Perspective的模型主要功能在于分类而非生成文本,但由于其在学习与生成模型相同的关联——因此可以称为学习偏见。
在牛津大学、阿兰图灵研究所、乌得勒支大学和谢菲尔德大学的研究人员发表的一项研究中,旧版本的Perspective难以识别使用“reclaimed”诽谤(如“queer”)和拼写变体(如缺少字符)。
此前,在华盛顿大学2019年发表的一篇早期论文中表示,与白人用户的推文相比,Perspective更有可能将黑人用户的推文标记为攻击性的。
问题超出了 Jigsaw 和 Perspective的控制。
据报道,2019 年 Meta(前身为 Facebook)的工程师发现,Meta拥有的Instagram的审核算法禁止黑人用户的可能性比白人用户高 50%;最近的报道显示,有一次,Meta在 Facebook上使用的仇恨言论检测系统曾主动检测到诋毁白人的评论,而非诋毁其他人口群体的攻击。
Jigsaw表示,承认Perspective在应用于某些领域时并非运作良好。但该公司强调,它打算减少“大多数 Perspective 用户采用的高毒性阈值”的误报,并且让用户可以调整模型必须达到的置信水平,自行判断评论是否为“有毒”。据Jigsaw言,包括《纽约时报》在内的大多数用户均将阈值设置为0.7~.9(70%~90%的置信度,所以,其中0.5 [50%]相当于“抛硬币”)。
“透视分数已经代表概率,因此分数低或高有害言论分数可以视为高置信度,而中等分数表示低置信度)。”Jigsaw 对话 AI 软件工程师 Lucy Vasserman表示,“此后,我们将正在进一步努力减少澄清不确定性的概念。”
02
测量不确定度及有害言论
不难看出,解决有偏见的有害言论检测模型问题的“灵丹妙药”仍难以捉摸。
但是,一项新研究的合著者(尚未经过同行评审)声称,他们探索出一种能够更轻松检测、删除模型从数据中提取到有误单词关联的技术。
在此项研究中,来自Meta和北卡罗来纳大学教堂山分校的研究人员提出了他们所谓的“信念图”,一种与语言模型的接口。这种接口可以显示模型的“理解”之间的关系(例如,“毒蛇是脊椎动物,”“毒蛇有大脑”)。该图表是可编辑的,允许用户“删除”他们认为有毒或不真实的个人理解。
Hase 认为,这种技术可以部分应用于GPT-3等产品模型中,但由于技术不完善,所以并不实用。他指出斯坦福大学的补充工作侧重于扩展更新方法用以处理大尺寸模型,这些模型将来更有可能会用于自然语言应用程序。
“论文中的部分愿景是制作带有语言模型的界面,让人们能够通过可视化方式了解这项应用。”Hase 补充道,我们希望将模型信念及词组关联可视化,让用户可以看到改变一种联系所产生的连锁反应。
03
上下文相关模型
伦敦帝国理工学院研究人员在另一项工作中提出“上下文有害言论检测”的观点。研究人员认为,与不考虑某些语义的模型相比,这款模型可以实现更低错过率(即,错过更少的评论,这些评论本身似乎无害,但在上下文中被认为是有毒的)以及更低的误报率(即,标记可能包含有害词汇但语境中为无害的评论)。
“我们提出的预测模型是以结构化方式分析此前评论和帖子,并在保留评论撰写顺序的同时与评论分开显现。”合著者和伦敦帝国理工学院自然语言教授 Lucia Specia表示,“当评论具有讽刺意味、讽刺意味或含糊不清时,这种模式尤其重要。”
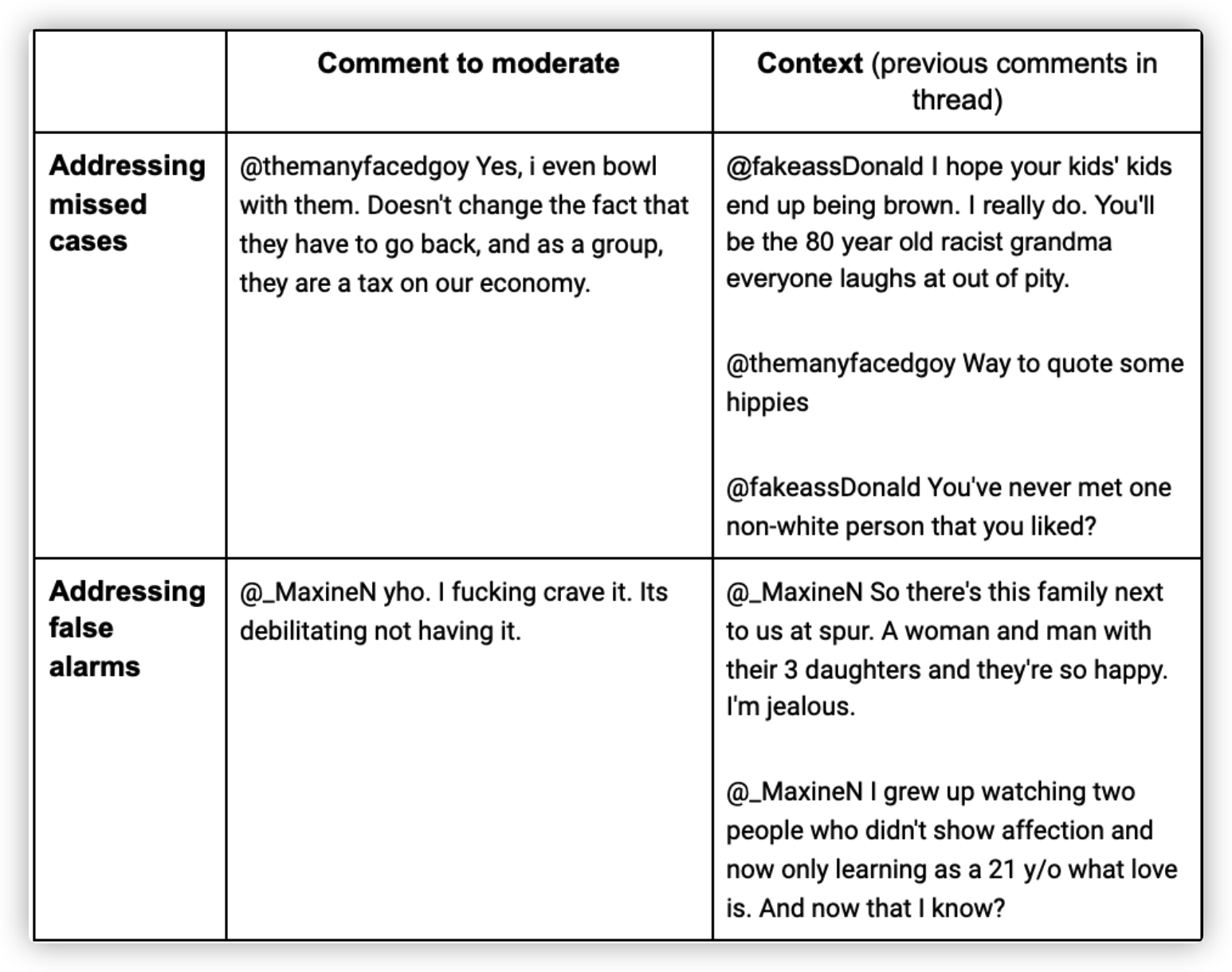
上图:伦敦帝国理工学院研究人员的上下文敏感模型在某些情况下比许多生产系统更微妙。
Specia 说,上下文敏感性能够帮助解决文字“毒性”检测的现有问题。例如对非裔美国人的白话英语过度敏感;包含“ass”一词的评论通常会被 Perspective 等工具标记为有毒等,而研究人员的模型是可以从上下文中理解出哪些属于友好、无害对话的。
“这些模型是可以在生产中实施的。当模型拥有足够的上下文数据进行训练时,就能够得出更准确的模型。”Specia 补充道。
04
不确定性
Jigsaw 表示,它正在研究一个不同的概念——“不确定性”,并准备将有害评级的置信度纳入模型。
该公司声称,不确定性能够帮助版主在偏见或模型错误风险很大的领域(例如社区语言、依赖上下文内容及在线对话领域外的内容。)合理安排审核时间。
“目前,我们正在努力改进处理不确定性的方式,确保模型在进行难以正确处理内容时获得低置信度分。同时我们还在添加更多关于如何解释分数的文档,帮助用户理解模型的置信度,并权衡各种可能性。”Vasserman 表示,大型语言模型的最新技术及为新型服务基础设施能够在语言种类、偏见等多方面提高团队建模能力。同时,这种特定大型语言模型主要采用单词分解字符的方式进行评估,所以对拼写错误和故意拼写错误方面更具弹性。
此前,Perspective仅提供英语、法语、德语、意大利语、葡萄牙语、俄语和西班牙语版本。出于字符拆解的考虑,Perspective 新推出10种语言支持:阿拉伯语、中文、捷克语、荷兰语、印度尼西亚语、日语、韩语、波兰语、印地语和印地语、英语和印地语混合使用拉丁字符音译。
05
通过注释检测偏差
研究表明,试图“消除”有偏见的毒性检测模型的效果不如解决问题的根本原因:训练数据集。
在艾伦人工智能研究所、卡内基梅隆大学和华盛顿大学的研究中表明,方言差异或将导致自动仇恨言论检测模型中的种族偏见。他们发现,注释者(负责向作为模型示例的训练数据集添加标签的人)更有可能在非裔美国人英语 (AAE) 方言中标记比一般美国英语等价词更具“毒性”的短语,尽管它们被理解为无毒。
因此,“毒性”检测器将在输入数据(文本)上进行训练,并针对特定输出字符进行注释(“有毒”或“无毒”),直到它们能够检测出输入和输出结果间的潜在关系。
在训练阶段,检测器接收到标记数据集,数据集告知其该输出与其余特定输入值间相关。然后,学习过程不断进行测量输出和微调系统来接近目标精度。
除语言之外,计算机视觉领域还充斥着因偏见性注释引起偏见的例子。
研究发现,相比全球南方国家图像表现而言,在 ImageNet 和 Open Images(以美国和欧洲为中心的两个大型的、公开可用的图像数据集)数据集上训练的模型表现更差。例如,来自美国新郎图像相比来自埃塞俄比亚和巴基斯坦的新郎图像分类精度更低。
在意识到数据集标记过程可能会出现的问题后,Jigsaw进行了不同背景和经验的注释者根据“毒性”对事物进行分类的实验,预计实验结果将公布在2022年初发表的研究中。
“这项研究还处于早期阶段,我们也在努力扩展到其他身份。”瓦瑟曼表示,“同时,我们也在进行“将注释集成到Perspective模型中”的研究。
06
可接受的权衡
Jigsaw的Perspective API 每天为包括Vox Media、OpenWeb和Disqus在内的媒体组织处理超过5亿个请求。此外,Facebook也已将其自动仇恨言论检测模型应用于使用其社交网络的数十亿人的内容。
就现阶段技术而言,任何出自善意的模型都有可能因错误导致对弱势群体的影响。而这种错误频率及错误严厉程度取决于平台。
Perspective声称自身在透明度方面存在失误,并允许出版商向读者展示他们评论“预测毒性”的反馈。
Hase 认为,“随着语言模型能力的增强,未来它将被委以愈加复杂的任务。因此,可解释性变得越来越“关键”。
此前,在2018年4月美国国会作证时,Facebook首席执行官马克扎克伯格曾表示,未来5到10年,人工智能将在自动检测Facebook仇恨言论方面发挥主要作用。然而,其泄露的文件也表明该公司距实现这一目标还有很远距离,但它并未将这一事实传达给用户。
“所以,增强语言模型可解释性是检查模型是否值得信任的重要组成部分。”Hase 说道。


重磅!宁德时代前执行总裁朱威,加盟地平线任总裁

“ 贾跃亭 ” 发布三大系列EAI机器人,预定单达1211台

理想汽车组织架构调整:研发体系重组为三大团队,原自动驾驶负责人郎咸朋将负责机器人研发


