本文发自“VentureBeat”,原题为“How low-code machine learning can power responsible AI”,作者Dattaraj Rao,Persistent Systems,经朋湖网作者王姿蝶编译整理,供业内参考。
随着科技的高速发展,基于AI技术的产品、工作流程逐步被银行、医疗保健、广告及众多人力和商业活动广泛采用。高精准度的人工智能模型成为此类产品在进行商业部署时的关键要素及所有企业关注的核心。
在创建AI解决方案透明度、问责制、公平性及安全性信任方面,采用“负责任”人工智能框架成为所有开发软件组织的侧重点。
事实上,促使AI“负责”的关键是拥有一个能够促进结果可重现性并对其进行数据及ML模型进行管理的谱系。
允许数据科学家用于特征工程、数据清理、模型开发和统计性能比较的预罐装模式——低代码机器学习在PyCaret、H2O.ai和DataRobot等工具中越来越受欢迎,然而,这些软件包中通常缺失“负责任”AI模式。在这里,我们演示了一种快速简便的方法,将PyCaret与Microsoft RAI(负责任的人工智能)框架集成,以生成一份详细的报告,显示错误分析、可解释性、因果关系和反事实。
01
代码演练
首先,我们安装了能够在Python 3.6+本地机器及Google Colab等SaaS平台上完成的库。
!pip install raiwidgets!pip install pycaret!pip install — upgrade pandas!pip install — upgrade numpy
当下,需要熊猫和Numpy升级,但修复速度很快。此外,如果您正在Google Colab中安装,请不要忘记重新启动运行时。
接下来,从GitHub加载数据,清理数据,并使用PyCaret进行功能工程。
import pandas as pd, numpy as npimport matplotlib.pyplot as plt%matplotlib inline
csv_url = ‘https://raw.githubusercontent.com/sahutkarsh/loan-prediction-analytics-vidhya/master/train.csv'
dataset_v1 = pd.read_csv (csv_url)dataset_v1 = dataset_v1.dropna()
from pycaret.classification import *
clf_setup = setup(data = dataset_v1, target = ‘Loan_Status’,
train_size=0.8, categorical_features=[‘Gender’, ‘Married’, ‘Education’,
‘Self_Employed’, ‘Property_Area’],
imputation_type=’simple’, categorical_imputation = ‘mode’, ignore_features=[‘Loan_ID’], fix_imbalance=True, silent=True, session_id=123)
该数据集是一个模拟贷款申请数据集,具有申请人的性别、婚姻状况、就业、收入等特征。PyCaret有一个很前卫的功能,可以通过get_config方法在功能工程后提供训练和测试数据帧。可以使用它来获取清洁功能,稍后将其反馈到RAI小部件中。
X_train = get_config(variable=”X_train”).reset_index().drop([‘index’], axis=1)y_train = get_config(variable=”y_train”).reset_index().drop([‘index’], axis=1)[‘Loan_Status’]
X_test = get_config(variable=”X_test”).reset_index().drop([‘index’], axis=1)y_test = get_config(variable=”y_test”).reset_index().drop([‘index’], axis=1)[‘Loan_Status’]
df_train = X_train.copy()df_train[‘LABEL’] = y_traindf_test = X_test.copy()df_test[‘LABEL’] = y_test
现在,我们运行PyCaret来构建多个模型,并将其作为统计性能指标在Recall上进行比较。
Top5_results = compare_models(n_select=5, sort='Recall')
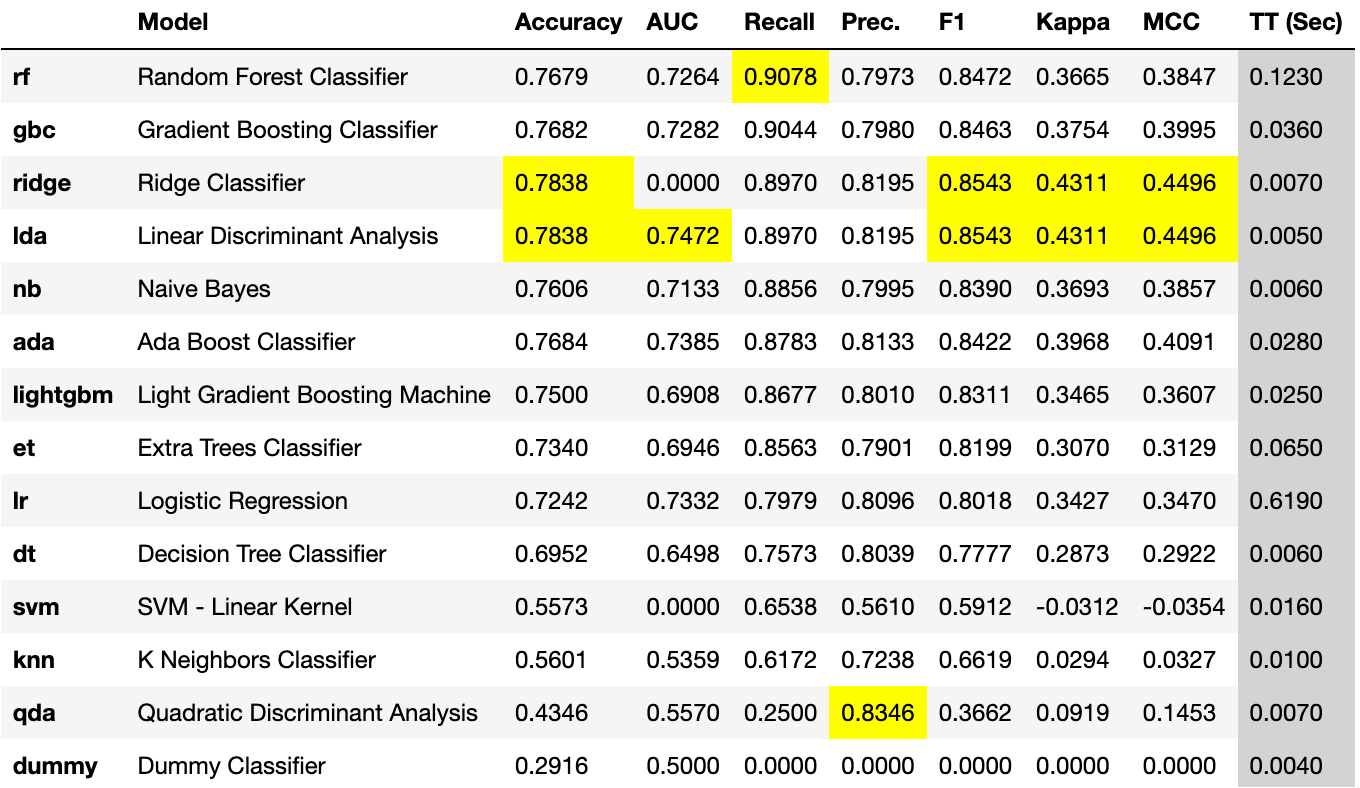
图1-召回时比较的PyCaret模型
顶级模型是一个随机森林分类器,召回0.9后可在此进行绘制。
Selected_model = top5_results[0]
Plot_model(selected_model)
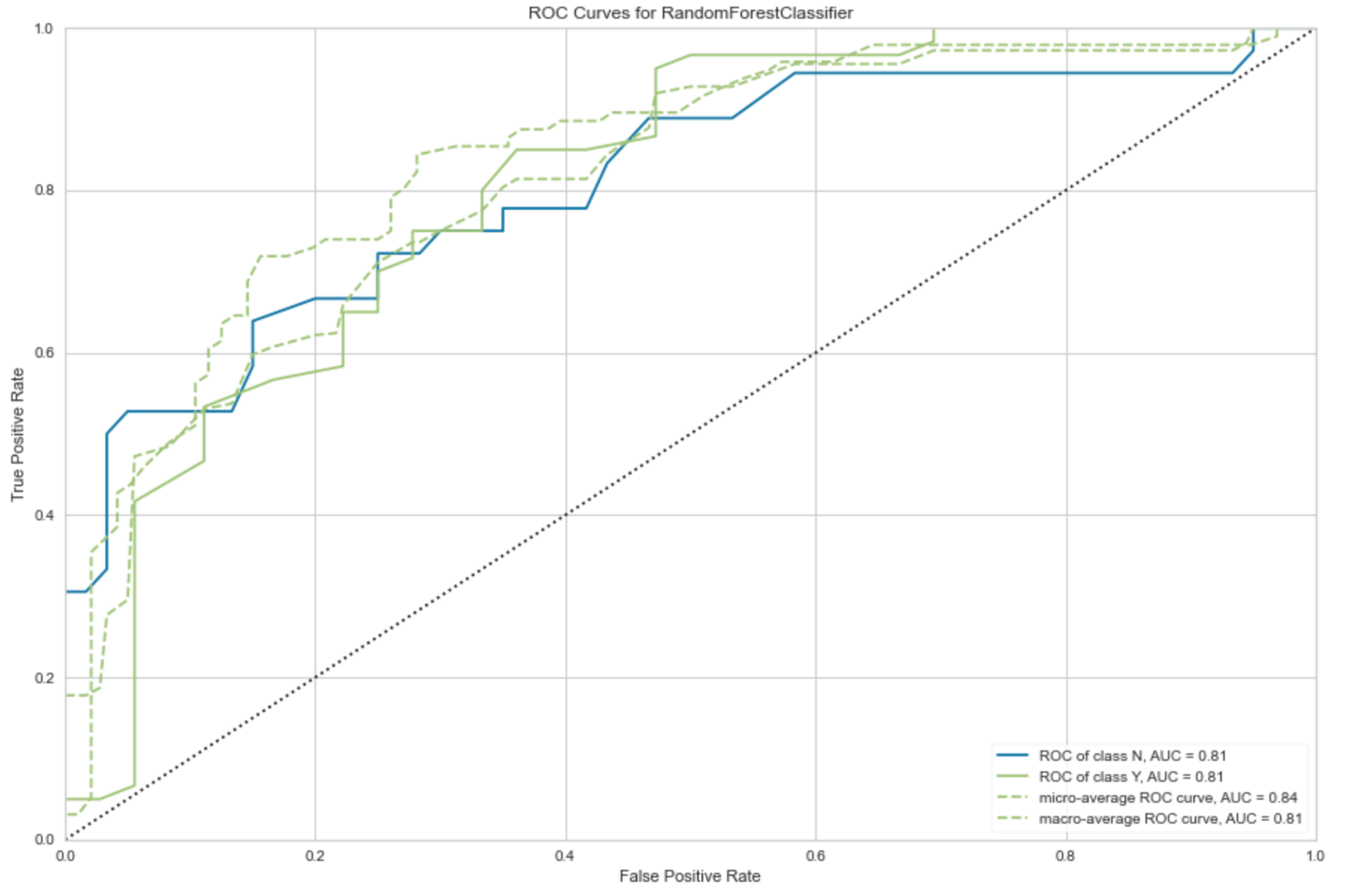 图2-所选模型的ROC曲线的AUC
图2-所选模型的ROC曲线的AUC
现在,将编写10行代码,使用从PyCaret生成的功能数据帧和模型构建RAI仪表板。
cat_cols = [‘Gender_Male’, ‘Married_Yes’, ‘Dependents_0’, ‘Dependents_1’, ‘Dependents_2’, ‘Dependents_3+’, ‘Education_Not Graduate’, ‘Self_Employed_Yes’, ‘Credit_History_1.0’, ‘Property_Area_Rural’, ‘Property_Area_Semiurban’, ‘Property_Area_Urban’]
from raiwidgets import ResponsibleAIDashboard
from responsibleai import RAIInsightsrai_insights = RAIInsights(selected_model, df_train, df_test, ‘LABEL’, ‘classification’,
categorical_features=cat_cols)
rai_insights.explainer.add()
rai_insights.error_analysis.add()
rai_insights.causal.add(treatment_features=[‘Credit_History_1.0’, ‘Married_Yes’])
rai_insights.counterfactual.add(total_CFs=10, desired_class=’opposite’)
rai_insights.compute()
上面的代码虽然简约,但却能起到许多作用。它分类创建有关RAI的见解,并添加了可解释性和错误分析的模块,并根据信用史和婚姻状况进行因果分析。此外,它还能够对10个场景进行反事实分析。
现在,让我们生成仪表板。
ResponsibleAIDashboard(rai_insights)
上述代码将在5000这样的端口上启动仪表板。在本地机器上,您可以直接访问http://localhost:5000并查看仪表板。在Google Colab上,仅需做一个简单的技巧来查看此仪表板。
from google.colab.output import eval_jsprint(eval_js(“google.colab.kernel.proxyPort(5000)”))
这将为您提供查看RAI仪表板的URL,同时在下面看到RAI仪表板的一些组件。以下是该分析的一些主要结果,这些结果是自动生成的,以补充PyCaret完成的AutoML分析。
02
结果:负责任的人工智能报告
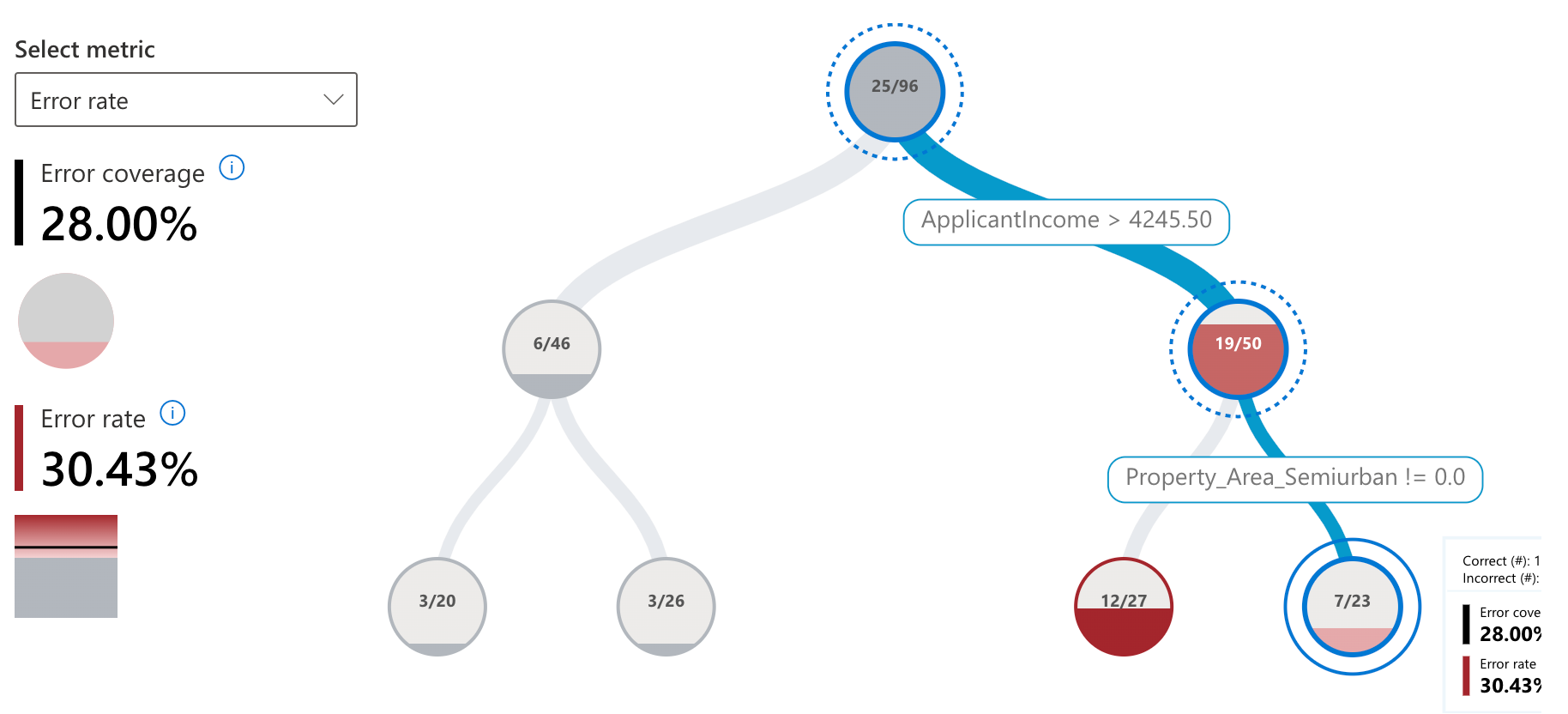
误差分析:我们发现农村房地产地区的误差率很高,我们的模型对这一特征有负偏差。
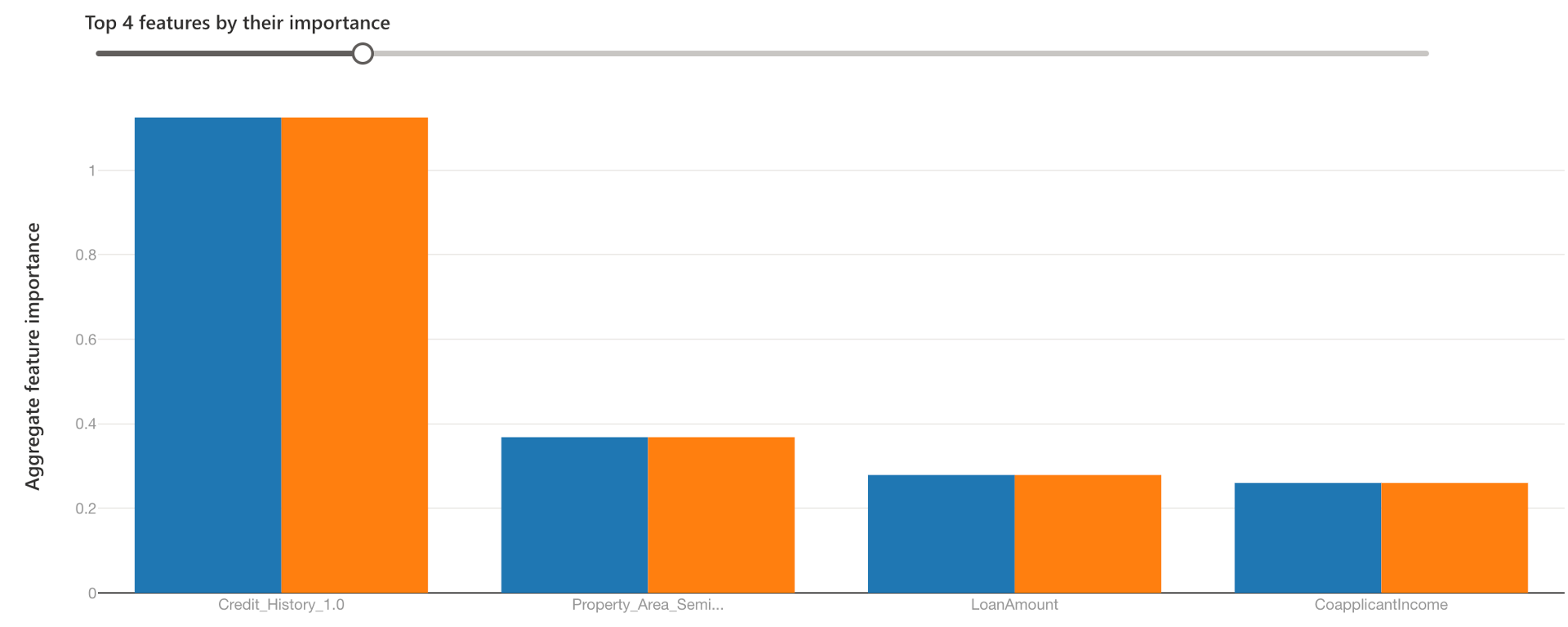
 全局可解释性-特征重要性:两个队列的特征重要性保持不变——所有数据(蓝色)和农村房地产区(橙色)。可以看到,对于橙色队列来说,房地产面积确实产生了更大的影响,但信用记录仍是第一因素。
全局可解释性-特征重要性:两个队列的特征重要性保持不变——所有数据(蓝色)和农村房地产区(橙色)。可以看到,对于橙色队列来说,房地产面积确实产生了更大的影响,但信用记录仍是第一因素。
本地可解释性:我们看到信用记录也是个人预测的一个重要特征——第20行。
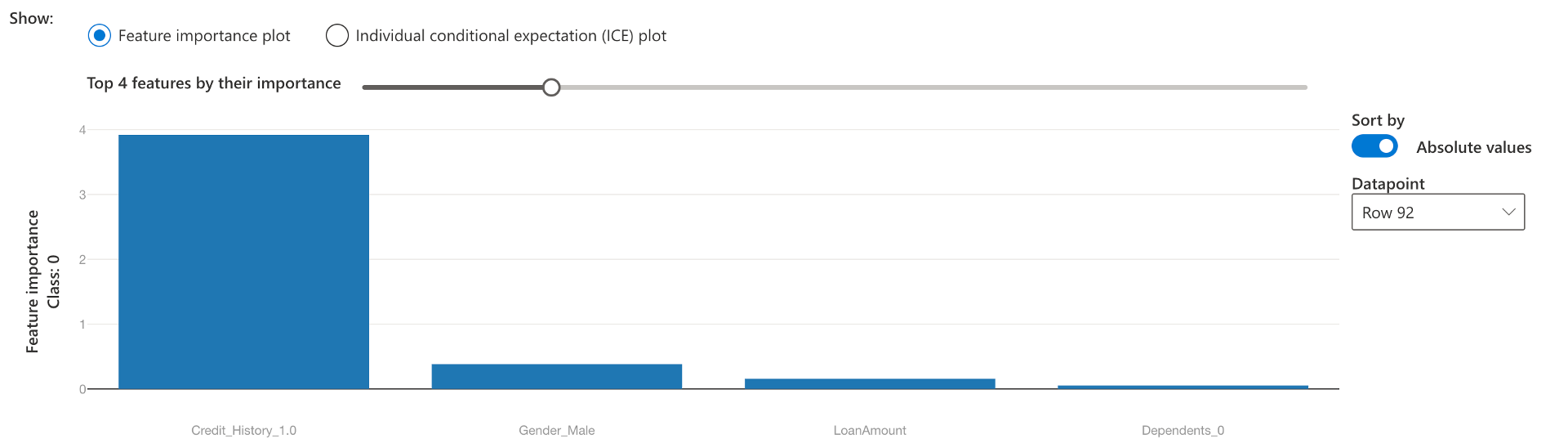
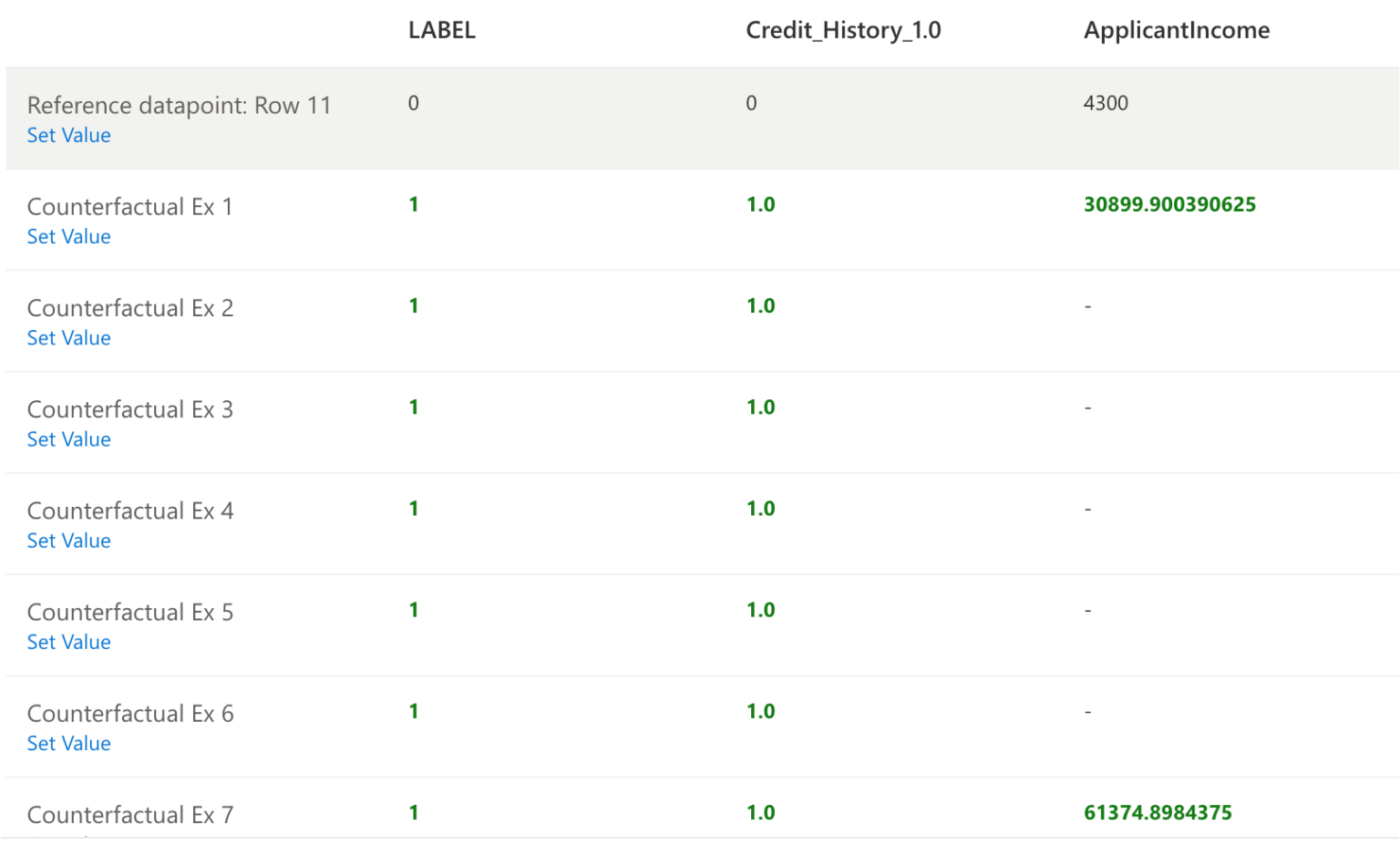
反事实分析:对于同一行#20信用记录和贷款金额发生变化,就可以从N到Y做出决定(基于数据)。
因果推断:通过因果分析来研究两种治疗方法的影响,即信用记录和就业状况,发现信用记录对批准有更大的直接影响。

显示模型误差分析、可解释性、因果推理和反事实负责任AI分析报告可以为传统的精确召回统计指标提升价值,通常可将其用作评估模型的杠杆。同时,使用PyCaret和RAI仪表板等现代工具就可以轻松构建这些报告。


重磅|2025机器人产业系列榜单正式发布

蜀道气体产业基金设立,20亿

刚刚!“ 字节跳动 ” 成为春晚独家AI云服务合作伙伴


